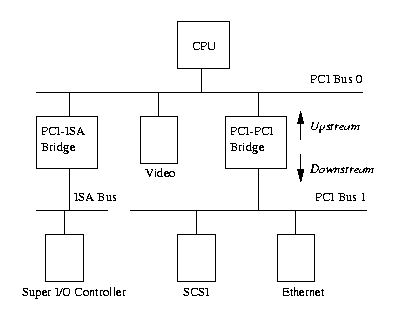
Page Frame Reclaiming Algorithm (PFRA )
From Understanding the Linux Kernel, chapter 17.
討論給定一個physical page, 如何得到誰再使用此page. 可能使用的有1. file cache, 2. process address space, 3. device cache. 然後根據某些heuristic來決定哪些page要先被釋放.
"The page frame reclaiming algorithm of the Linux kernel refills the lists of free blocks of the buddy system by "stealing" page frames from both User Mode processes and kernel caches."
- 所以可以從user mode process 或是kernel cache來選擇要回收的papge.
Page type:
Anonymous page:
A page is said to be anonymous if it belongs to an anonymous memory region of a process (for instance, all pages in the User Mode heap or stack of a process are anonymous)
Mapped page: a page is mapped to a file.
For instance, all pages in the User Mode address spaces belonging to file memory mappings are mapped, as well as any other page included in the page cache.
Anonymous Page Reclaim
當kernel要做page reclaim時, 給定一個physical page,要找到使用此page的process, 如果只有單一process, 那此page就是non-shared, 如果有多個, 就是shared anonymous page.
判斷anonymous page的方法
struct page {
_mapcount: if >=0, 代表多個process share此page
struct address_space *mapping: 如果= NULL, -> anonymous page. Else -> mapped to a file (inode)
}
mapping: Pointer to the owning object
Shared and non-shared
如果此page是anonymous page: kernel keeps a list called anon_vma.
anon_vma是一個list, 儲存所有來自不同process的vm_area_struct但指到同一個page, 所以這是shared的anonymous page. 當kernel需要free anonymous pages時, 可以經由此list找到所有的相關的process, 拿到vm_area_struct, 然後invalidate他的page table.
"We have seen in the previous section that descriptors for anonymous memory regions are collected in doubly linked circular lists; retrieving all page table entries referencing a given page frame involves a linear scanning of the elements in the list. The number of shared anonymous page frames is never very large, hence this approach works well." from ref2:
From ref2, fig17-1: 兩個process (mm_struct) share 同一個page, anon_vma用來連結所有shared此page的vm_area_struct.
當要釋放page時, 必須要iterate all vm_area_struct, 找到他對應的page table, do linear scanning, 然後swap out or write tot disk.
Mapped Page Reclaim
Problem1: 給定一個要reclaim的page, 此page是被一個file mapped. 此時必須找出在file的哪個offset對應到此page.
如果是mapped page: 利用struct page裡面的struct address_space mapping可以拿到inode. address_space有radix_tree_root, radix tree上面對應file offset到page cache的位置. 當所對應的page被釋放後, address_space裡面的radix tree需要被更新 (變成NULL).
Problem2: 找到此file offset之後, 可能很多個process都透過mmap來對應到此file offset, ex:libc
Idea: 假設跟anonymous page一樣, 利用一個list來存所有的vma
Complication1:
Not all file mappings map the entire file
假設要page 4 of a file, 必須要filter all vma that don't include page 4
Complication2: anonymous mappings won’t be shared much
anonymous page很少被shared, 除非利用fork, mapped file常常被shared, ex: libc
Problem: Lots of entries on the list + many that might not overlap
Solution: Priority Search Tree
Idea: binary search tree that uses overlapping ranges as node keys
Bigger, enclosing ranges are the parents, smaller ranges are children
Use case: Search for all ranges that include page N
三種Tree的不同用法
1. Radix tree: (inode -> physical memory)
file(inode)的page cache. 處理file(inode)到address space的maping. inode有i_mapping (struct address_space), address_space有radix_tree_root
struct address_space {
635 struct inode *host;
636 struct radix_tree_root page_tree; ...
從此page_tree得到file offset對physical memory的mapping.
2. Red-black tree: (process address space -> page)
處理process address space的mapping. 每個process有mm_struct, mm_struct用來管理所有的vm_area_struct, 把所有的vm_area_struct存在一個list. (note: red-black tree is balanced.)
from ref1:
3. Priority tree (process address space -> file)
"There is a priority search tree for every file; its root is stored in the i_mmap field of the address_space object embedded in the file's inode object. It is always possible to quickly retrieve the root of the search tree, because the mapping field in the descriptor of a mapped page points to the address_space object. " from ref2
case: mapped anonymous page
很多program利用mmap將file直接map到process的address space. Example: libc就是很常見的例子. (所以這不是file page cache, 也不是process address space page mapping) 然而每個program可能只有map libc file的某個部份, 並不會把整個file全部map到自己program的address space. 因此Linux利用 PST(Priority Search Tree) 來管理這個mapping.
from ref2 fig17-2:
Goal: 給定一個file offset, 找到哪些vm_area_struct有包含此file offset (透過mmap).
Each node in the PST contains a list of vmas mapping that interval. 每個node代表一個interval, 而每個node裡面的list of vm_area_struct都map到此interval.
下圖為file page 0 ~ 5.
Radix: interval的起始位置, heap: interval的終止位置
條件: 1. parent heap number > child heap number. 2. 左邊的radix number > 右邊radix number
Traversal for page n:
if n > heap number, stop
else
if n is in the range of radix and heap, it's the answer
continue checking ALL the children.
example: n = 4
4 < 5 and 4 is in (0,5) -> (0,5,5), 4<=4-> (0,4,4), 4 > 0, 4 >2, 4 < 5 and 4 is in (2,5) -> (2,3,5), 4>3, 4>2
下圖右上角為inode, inode指向struct prio_tree i_mmap, i_mmap指向一個priority tree. Priority tree紀錄了這個file裡面每個file offset page對應到process的mm_struct. 而每個mm_struct包含多個vm_area_struct. 由此可知如何從一個file inode找到所有對此file使用mmap的process.
From ref1, fig 4-7:
struct address_space {
635 struct inode *host;
636 struct radix_tree_root page_tree;
637 spinlock_t tree_lock;
638 unsigned int i_mmap_writable;
639 struct prio_tree_root i_mmap;
640 struct list_head i_mmap_nonlinear;
LRU (Least Recent Use)
所有的page都分別屬於兩個LRU list: active or inactive, 當此page有備access到就移到active list. 如果很久沒被用就移到inactive.
- Anonymous page是user space在使用的, kernel必須要知道此page是否經常被使用, 如果很少被使用就可以被reclaim.
- Page table entry裡面有個access bit, 當此page table entry被access時, x86 hardware會set this bit, 用來通知linux kernel. Kernel periodically reset and check this bit to know whether this page is frequently used.
Page Reclaim Heuristics:
cases: low memory, hibernate, free memory below a threshold.
要先選哪個page來釋放?
goal: minimize the performance disruption.
1. Free harmless pages first
2. Steal pages from user programs, especially those that haven’t been used recently
- page reclaim之後要remove all reference to the page
3. Laziness:Favor pages that are “cheaper” to free
- Waiting on write back of dirty data takes time
Reference:
1. Professional Linux Kernel Architecture, chapter 4.
2. Understanding the Linux Kernel, chapter 17.
3. Segment tree: http://en.wikipedia.org/wiki/Segment_tree (or Priority tree)