However, it seems that the Ethernet driver does not leverage the DMA channel to do data movement between back-to-back connected hosts. To understand the Intel DMA's performance, I've tested the Intel's DMA engine, aka Quickdata technology.
System Description:
I'm testing using Intel(R) Xeon(R) CPU E5-2620 0 @ 2.00GHz, with 8GB memory. For both experiment, the PCIe max payload size is set to 128 byte.
Two experiments are shown:
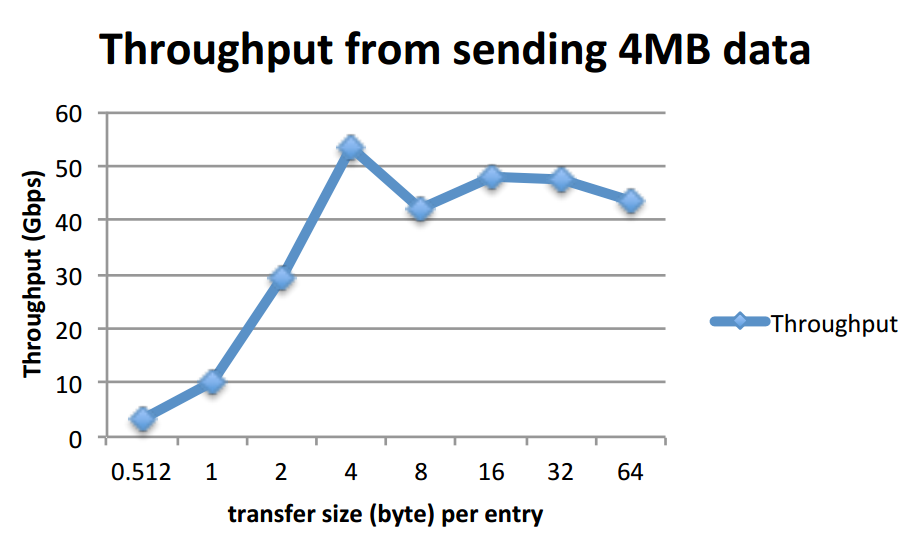
1) send total amount of payload 4MB (non-continuous), with different transfer size per DMA entry. Ex: 4KB transfer size results in 1024 entries to make a 4MB. (X-axis is K-byte, not byte)
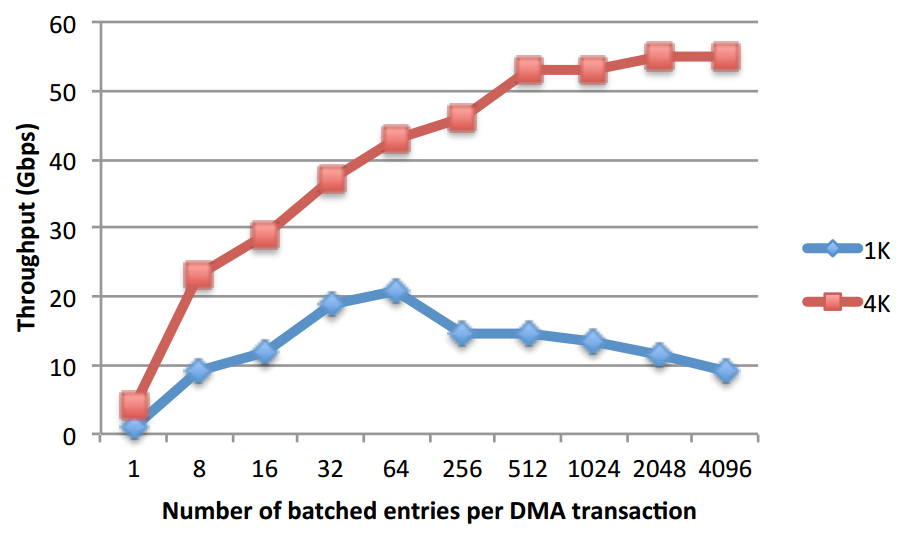
 2) With a particular transfer size per entry, batch number of entries per DMA transaction. Ex: 4KB transfer size per entry, batching 1024 entries in one DMA transaction.
2) With a particular transfer size per entry, batch number of entries per DMA transaction. Ex: 4KB transfer size per entry, batching 1024 entries in one DMA transaction.
Short Summary:
I did not setup the NTB so these experiments are local to local memory copy. The best performance is around 54Gbps using > 4KB per entry transfer size to copy 4MB data. Copying 1KB data for 1 entry takes 8 us. Compared to PLX's DMA which has around 20Gbps local to local memory copy bandwidth under 128B MaxPayload size, Intel's DMA seems to outperform a lot.
System Description:
I'm testing using Intel(R) Xeon(R) CPU E5-2620 0 @ 2.00GHz, with 8GB memory. For both experiment, the PCIe max payload size is set to 128 byte.
Two experiments are shown:
1) send total amount of payload 4MB (non-continuous), with different transfer size per DMA entry. Ex: 4KB transfer size results in 1024 entries to make a 4MB. (X-axis is K-byte, not byte)
Short Summary:
I did not setup the NTB so these experiments are local to local memory copy. The best performance is around 54Gbps using > 4KB per entry transfer size to copy 4MB data. Copying 1KB data for 1 entry takes 8 us. Compared to PLX's DMA which has around 20Gbps local to local memory copy bandwidth under 128B MaxPayload size, Intel's DMA seems to outperform a lot.
The throughput increases as the transfer size per entry increase. I think this is due to the maximum number of outstanding read request, usually set to 32. If all PCIe TLPs need to break down into 128 byte maximum payload size, then the 32 outstanding pending requests means 128B * 32 = 4KB, which explains why the throughput saturates at 4KB transfer size per entry.
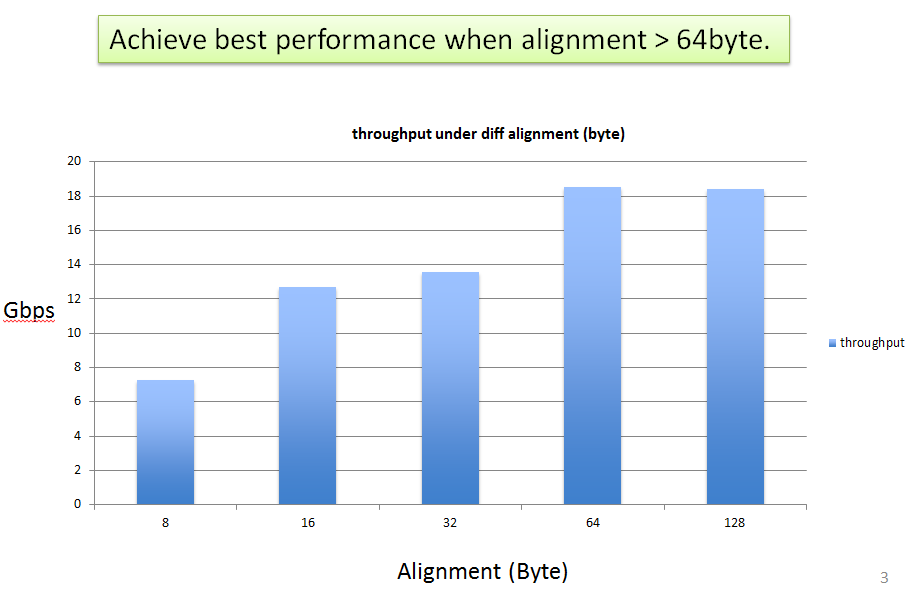
I did not test the effect of address alignment under Intel's DMA, however, we've found the the address alignment matters a lot to the performance under the PLX's DMA engine.
Source code:
#include <linux/sched.h>
#include <linux/pci.h>
#include <linux/ioport.h>
#include <linux/init.h>
#include <linux/dmi.h>
#include <linux/slab.h>
#include <linux/init.h>
#include <linux/module.h>
#include <linux/dmaengine.h>
#include <linux/async_tx.h>
#include <linux/kernel.h>
#include <linux/highmem.h>
#include <linux/mm.h>
#include <linux/dma-mapping.h>
#include <linux/async_tx.h>
#define RAND_BASE 1024
#define GB (1<<30)
#define MB (1<<20)
#define KB (1<<10)
MODULE_LICENSE("GPL");
static void callback(void *param)
{
if (!param)
printk("NULL param\n");
struct dma_async_tx_descriptor *tx =
(struct dma_async_tx_descriptor *)param;
return;
}
#include <linux/sched.h>
#include <linux/pci.h>
#include <linux/ioport.h>
#include <linux/init.h>
#include <linux/dmi.h>
#include <linux/slab.h>
#include <linux/init.h>
#include <linux/module.h>
#include <linux/dmaengine.h>
#include <linux/async_tx.h>
#include <linux/kernel.h>
#include <linux/highmem.h>
#include <linux/mm.h>
#include <linux/dma-mapping.h>
#include <linux/async_tx.h>
#define RAND_BASE 1024
#define GB (1<<30)
#define MB (1<<20)
#define KB (1<<10)
MODULE_LICENSE("GPL");
static void callback(void *param)
{
if (!param)
printk("NULL param\n");
struct dma_async_tx_descriptor *tx =
(struct dma_async_tx_descriptor *)param;
return;
}
dma_cookie_t
itri_dma_async_memcpy(struct dma_chan *chan, void *dest,
void *src, size_t len)
{
struct dma_device *dev = chan->device;
struct dma_async_tx_descriptor *tx;
dma_addr_t dma_dest, dma_src;
dma_cookie_t cookie;
unsigned long flags;
dma_src = dma_map_single(dev->dev, src, len, DMA_TO_DEVICE);
dma_dest = dma_map_single(dev->dev, dest, len, DMA_FROM_DEVICE);
flags = DMA_CTRL_ACK |
DMA_COMPL_SRC_UNMAP_SINGLE |
DMA_COMPL_DEST_UNMAP_SINGLE;
tx = dev->device_prep_dma_memcpy(chan, dma_dest, dma_src, len, flags);
if (!tx) {
dma_unmap_single(dev->dev, dma_src, len, DMA_TO_DEVICE);
dma_unmap_single(dev->dev, dma_dest, len, DMA_FROM_DEVICE);
return -ENOMEM;
}
tx->callback = NULL;
//tx->callback = callback;
//tx->callback_param = tx; //william
cookie = tx->tx_submit(tx);
preempt_disable();
__this_cpu_add(chan->local->bytes_transferred, len);
__this_cpu_inc(chan->local->memcpy_count);
preempt_enable();
return cookie;
}
int dma_throughput_test(int tr_size, unsigned long total_size)
{
int i, num_entry;
void *src, *dst, *ran_src, *ran_dst;
unsigned long offset, total_usec, ts;
static struct timeval time_e, time_s;
struct dma_chan *chan;
dma_cookie_t cookie;
dmaengine_get();
chan = dma_find_channel(DMA_MEMCPY);
if (!chan)
return -ENODEV;
num_entry = total_size / tr_size;
if (num_entry <= 0)
return -ENOMEM;
src = kmalloc(tr_size * RAND_BASE, GFP_KERNEL);
if (!src)
return -ENOMEM;
dst = kmalloc(tr_size * RAND_BASE, GFP_KERNEL);
if (!dst) {
kfree(src);
return -ENOMEM;
}
memset(dst, 0xff, tr_size * RAND_BASE);
do_gettimeofday(&time_s);
for (i = 0; i < num_entry; i++) {
offset = (i % RAND_BASE) * tr_size;
offset = (ts % RAND_BASE) * tr_size;
if (offset >= RAND_BASE * tr_size) {
pr_err("Invalid addr\n");
return -EINVAL;
}
ran_src = src + offset;
ran_dst = dst + offset;
cookie = itri_dma_async_memcpy(chan, ran_dst, ran_src, tr_size);
if (cookie < 0) {
kfree(src);
kfree(dst);
printk("Invalid cookie\n");
return -EINVAL;
}
// dma_sync_wait(chan, cookie);
}
dma_issue_pending_all();
dma_sync_wait(chan, cookie);
do_gettimeofday(&time_e);
total_usec = (time_e.tv_sec - time_s.tv_sec) * 1000 * 1000
+ (time_e.tv_usec - time_s.tv_usec);
printk(KERN_EMERG "Local2Local DMA %6d entry, per entry size %3dKB, "
"total size: %6ldKB, take %6ld us, bandwidth %6ldMbps\n",
num_entry, tr_size / (1<<10), total_size / (1<<10),
total_usec, total_size * 8 / (total_usec)
);
kfree(src);
kfree(dst);
dma_issue_pending_all(); //flush all pending descriptor
dmaengine_put();
return 0;
}
void test_fixed_total_entry(void)
{
// assume run time should be the same
dma_throughput_test(1 * KB, 10 * MB);
dma_throughput_test(2 * KB, 20 * MB);
dma_throughput_test(4 * KB, 40 * MB);
dma_throughput_test(8 * KB, 80 * MB);
dma_throughput_test(16 * KB, 160 * MB);
return;
}
void test_throughput(void)
{
dma_throughput_test(128 , 4UL * GB);
dma_throughput_test(256 , 4UL * GB);
dma_throughput_test(512 , 4UL * GB);
dma_throughput_test(1024 , 4UL * GB);
return;
}
static int itri_dma_init(void)
{
test_fixed_total_entry();
test_throughput();
return 0;
}
static void itri_dma_exit(void)
{
printk(KERN_INFO "unloading itri dma\n");
return;
}
module_init(itri_dma_init);
module_exit(itri_dma_exit);